import pymc as pm
import numpy as np
import arviz as az
import matplotlib.pyplot as plt
import xarray as xr
import pandas as pd
8. Cumulative Example*#
Adapted from Unit 9: cumulative2.odc.
Notes#
From the OpenBUGS manual:
cumulative(s1, s2): tail area of distribution of s1 up to the value of s2, s1 must be stochastic, s1 and s2 can be the same
Fitting the model#
As we said on the previous page, we want to evaluate the Empirical CDF at the values of our response variable to check how well our model fits the data. First, we’ll fit our model and add posterior predictive samples to the trace.
# fmt: off
y = np.array(
[
0.0, 1.0, 2.0, -1.0, 0.4, -0.5, 0.7, -1.2, 0.1, -0.4,
0.2, -0.5, -1.4, 1.8, 0.2, 0.3, -0.6, 1.1, 5.1, -6.3
]
)
# fmt: on
with pm.Model() as model:
# Priors
theta = pm.Flat("theta")
ls = pm.Flat("ls")
s = pm.math.exp(ls)
# Likelihood
pm.Normal("y", mu=theta, sigma=s, observed=y)
# Sampling
trace = pm.sample(2000)
pm.sample_posterior_predictive(trace, extend_inferencedata=True)
pm.compute_log_likelihood(trace)
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [theta, ls]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 1 seconds.
Sampling: [y]
az.summary(trace)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| theta | 0.047 | 0.483 | -0.828 | 0.984 | 0.006 | 0.006 | 6462.0 | 5336.0 | 1.0 |
| ls | 0.753 | 0.168 | 0.452 | 1.078 | 0.002 | 0.002 | 5884.0 | 4996.0 | 1.0 |
Plot posterior predictive distribution vs. observed values#
Now we have posterior samples, the equivalent of the stochastic part of the y[i] node in BUGS. There are different ways to compare these with our ECDF. The easiest is the arviz.plot_ppc function with the kind="cumulative" argument.
az.plot_ppc(trace, kind="cumulative", num_pp_samples=100)
plt.show()
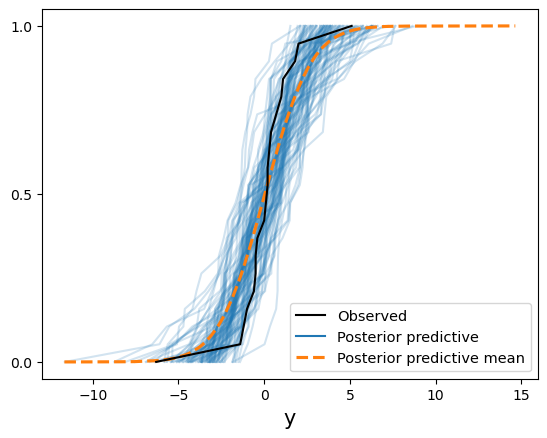
Doesn’t look like our posterior does a good job of fitting the observed data. The mean fits okay, but both tails have some issues because of some extreme values near the endpoints. This plot is just comparing individual ECDFs, though. It’s not evaluating the posterior ECDF at the observed \(y\) values.
Plots in general might not be the easiest thing to interpret if we have a lot of datapoints. I wrote the following function to recreate the lecture example.
Show code cell source
def evaluate_ecdf(trace: az.InferenceData) -> np.array:
"""Evaluates ECDF at original observed values.
This function assumes a single set of observed values.
Args:
trace: arviz.InferenceData from running a PyMC model.
Returns:
A Numpy array of the ECDF evaluation at each original datapoint.
"""
# get posterior predictive variable name
ppc_vars = list(trace.posterior_predictive.data_vars)
assert (
len(ppc_vars) == 1
), "Number of variables in posterior predictive must equal 1."
y_varname = ppc_vars[0]
# get original observations
y_obs = trace.observed_data[y_varname].values
assert (
len(y_obs.shape) == 1
), "Y-observations shape must be one-dimensional."
n_obs = y_obs.shape[0]
y_obs = y_obs.reshape(-1, 1) # for broadcasting
# get posterior predictive samples for each y_obs and sample count
y_samples_per_obs = trace.posterior_predictive[y_varname].stack(
sample=("chain", "draw")
)
assert y_samples_per_obs.shape[0] == n_obs, "Shape assumptions aren't met."
n_samples = y_samples_per_obs.shape[1]
# evaluate ECDF at each y_obs and convert to numpy array
ecdf_values = y_samples_per_obs <= y_obs
prob = ecdf_values.sum(dim="sample") / n_samples
return prob.to_numpy()
prob_ecdf_pit = evaluate_ecdf(trace)
loo_pit_output = az.loo_pit(trace, y="y")
df_results = pd.DataFrame(
{"y": y, "loo_pit": loo_pit_output, "ecdf_pit": prob_ecdf_pit}
)
df_results["squared_logit"] = np.log(prob_ecdf_pit / (1 - prob_ecdf_pit)) ** 2
df_display = df_results.sort_values(by="squared_logit", ascending=False)
df_display.style.format(
subset=df_display.select_dtypes("number").columns, formatter="{:.3f}"
).background_gradient(
subset=["loo_pit", "ecdf_pit"],
cmap="binary",
vmin=0.0,
vmax=1.0,
)
| y | loo_pit | ecdf_pit | squared_logit | |
|---|---|---|---|---|
| 19 | -6.300 | 0.000 | 0.005 | 28.567 |
| 18 | 5.100 | 0.995 | 0.985 | 17.302 |
| 2 | 2.000 | 0.823 | 0.812 | 2.141 |
| 13 | 1.800 | 0.801 | 0.792 | 1.788 |
| 12 | -1.400 | 0.236 | 0.241 | 1.311 |
| 7 | -1.200 | 0.277 | 0.282 | 0.876 |
| 17 | 1.100 | 0.696 | 0.692 | 0.653 |
| 3 | -1.000 | 0.309 | 0.315 | 0.607 |
| 1 | 1.000 | 0.678 | 0.675 | 0.533 |
| 6 | 0.700 | 0.627 | 0.624 | 0.257 |
| 16 | -0.600 | 0.383 | 0.384 | 0.222 |
| 5 | -0.500 | 0.396 | 0.399 | 0.168 |
| 11 | -0.500 | 0.399 | 0.402 | 0.157 |
| 9 | -0.400 | 0.426 | 0.427 | 0.085 |
| 4 | 0.400 | 0.567 | 0.566 | 0.071 |
| 15 | 0.300 | 0.550 | 0.550 | 0.040 |
| 14 | 0.200 | 0.530 | 0.530 | 0.014 |
| 10 | 0.200 | 0.528 | 0.527 | 0.012 |
| 0 | 0.000 | 0.496 | 0.498 | 0.000 |
| 8 | 0.100 | 0.500 | 0.500 | 0.000 |
The last two values (indices 18 and 19) are the outliers. Notice the squared logit transformation is useful because it’s sortable by magnitude.
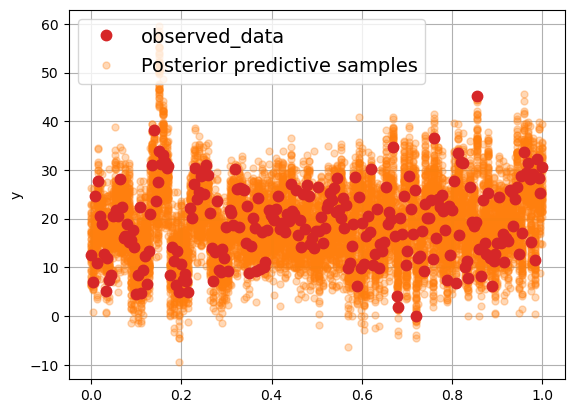
Another cool Arviz plot#
Arviz has the plot_lm function as well. It’s really nice for visualizing the observed data versus the posterior predictive samples. Let’s try it with the single-predictor model from 11. Brozek index prediction*.
data = pd.read_csv("../data/fat.tsv", sep="\t")
y = data["y"].to_numpy(copy=True)
X = data["X8"].to_numpy(copy=True)
with pm.Model():
sigma = pm.Exponential("sigma", 0.05)
beta0 = pm.Normal("intercept", 0, sigma=10)
beta1 = pm.Normal("slope", 0, sigma=10)
mu = beta0 + beta1 * X
likelihood = pm.Normal("y", mu=mu, sigma=sigma, observed=y)
trace = pm.sample(2000)
pm.sample_posterior_predictive(trace, extend_inferencedata=True)
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, intercept, slope]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 2 seconds.
Sampling: [y]
x = xr.DataArray(np.linspace(0, 1, 252))
trace.posterior["y_model"] = (
trace.posterior["intercept"] + trace.posterior["slope"] * x
)
az.plot_lm(idata=trace, y="y", x=x)
Show code cell output
array([[<Axes: ylabel='y'>]], dtype=object)
%load_ext watermark
%watermark -n -u -v -iv -p pytensor
Last updated: Thu Apr 03 2025
Python implementation: CPython
Python version : 3.12.7
IPython version : 8.29.0
pytensor: 2.30.2
pymc : 5.22.0
xarray : 2024.11.0
matplotlib: 3.9.2
pandas : 2.2.3
numpy : 1.26.4
arviz : 0.21.0